当社のインド法人 System Consultant Information India(P) Ltd.(略称SCII)では、最新技術にも取り組んでいます。その中から今回は、画像PDFからデータを読み取る機械学習の実装についてご紹介いたします。

請求書はPDFが主流

コロナ禍以来、書面の受け渡しが大幅に減少し、PDFでの送受信が増えています。PDFの場合、テキストデータでの送受信とは異なり、そのまま自社システムに取り込むことができません。
PDFを見ながら、自社のシステムに手入力している。そんな運用が、皆さまのオフィスでも多いのではないでしょうか。
OCRは機械学習で
”手入力にかかる人的時間的コストを削減し、同時にヒューマンエラーも回避したい”
そんな思いからSCIIでは、機械学習による請求書の画像PDFのOCR読み取り機能を構築し、さらに学習を積ませることで、請求書PDFから高い精度での自動データ抽出を実現し、かつ様々な形式の請求書でも、データの読み取りを可能としています。
今回構築した機能は、機械学習による物体検出とOCRでのデータ抽出を組み合わせて、画像PDFとして送られてきた請求書をデータに変換する、というものです。
機械学習の流れ
今回の機械学習は、「データ準備→前処理→モデルの学習→モデルの評価」という順序で行っています。
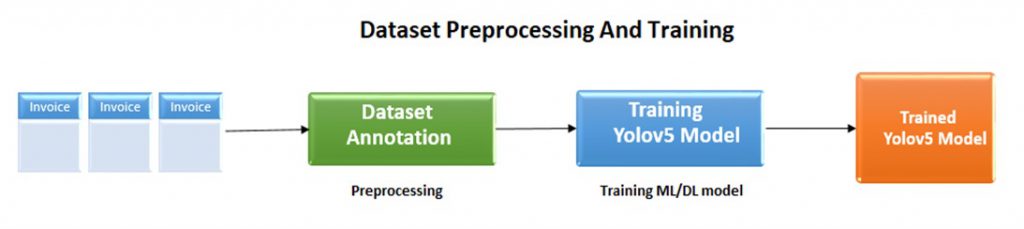
データ準備
SCIIで受領した請求書PDFを収集します。今回は「airtel」社からSCIIが受領した回線使用料金の請求書PDFを基本として、その他の請求書も使用しました。月ごとの請求額とその明細がPDFに記載されています。
前処理
教師データ用の請求書にアノテーションを行います。今回の「airtel」社の請求書PDFでは、請求元会社名、月額請求金額、月次明細の位置をポイントしました。
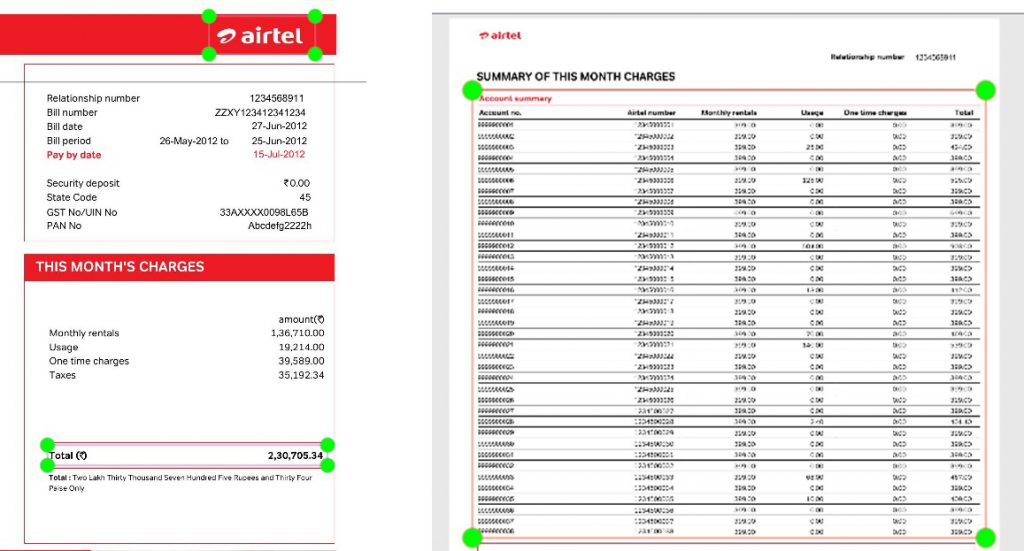

モデルの学習
Yolo v5を使って「airtel」社の請求書PDFの学習を行います。請求書PDFを訓練データとテストデータに分ける、ホールド・アウト法を採用しました。
他にもタイプが異なる様々な請求書を集め、それらにも、最適なアノテーションを行って教師あり学習として使用しています。
モデルの評価
様々な形式の請求書を訓練データ、テストデータとして学習した結果、請求元会社名、月額請求金額および明細テーブル部分をクロップすることはできており、請求元会社名、月額請求金額は内容の把握も高い確率で検出、抽出が可能でした。
しかし、明細部分はテーブル状になっており、列は罫線で区切られていないため、学習効果が上がらず、検出が困難であることが判明しました。
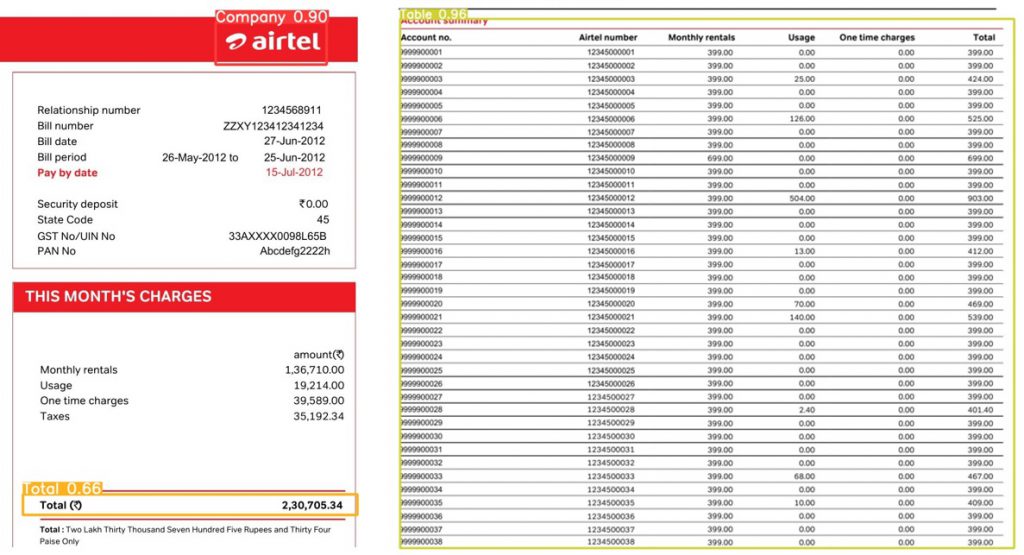
そこで、Microsoft社の「Table Transformer」を使用して明細の請求部分を抽出する学習を行いました。「Table Transformer」はテーブルを学習済なライブラリで、今回の明細把握には最適であると思い採用しました。これにより学習の精度は上がったものの、それでもまだ目標とする精度には達していないのが現状です。
さらに「Table Transformer」を今回対象とした請求書を活用して学習させられないか、SCIIでR&Dを進めております。
お問い合わせはこちらまで
当社のAI技術のご活用にご興味がおありでしたら、当社第一営業部までご連絡をお願い申し上げます。

最後までお読みいただき
ありがとうございました。