本ブログは、当社配信のメールマガジン【生成AIの復習シリーズ】を、加筆修正して再編集したものです。
<目次>
- 生成AIってなに?
- LLMってなに?
- Transformerとは
- Transformerの構造
- 「Transformer」とChatGP「T」の相違点
- LLMの課題とは
- 課題解決の方法
- 当社の課題解決の方法
- LLMの今後は
◆生成AIってなに?
生成AIは、文字通りAI=人工知能(Artificial Intelligence)の一種で、テキストや画像などの様々なコンテンツを生成する機能を持ったAI技術です。
#余談ですが、「AI」の定義は研究者によって様々で、統一されていないそうです。
生成AIは、生成するコンテンツによって、言語生成AI、画像生成AI、音声生成AI、音楽生成AI、動画生成AIなどに分類できます。
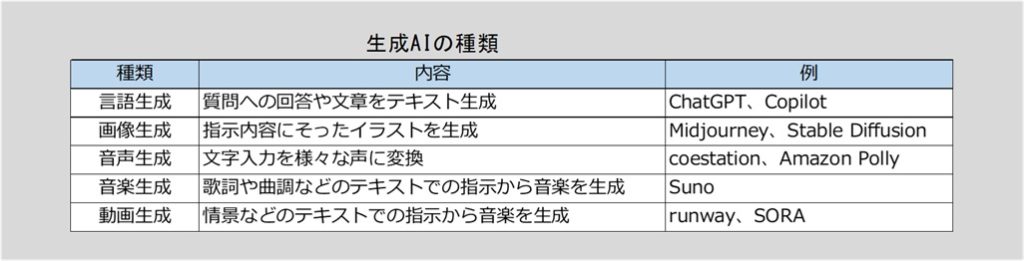
ChatGPTは対話型の言語生成AIで、大規模言語モデル(Large Language Model=LLM)を活用しています。
◆LLMってなに?

LLM(大規模言語モデル)とは、自然言語処理(NLP)という分野の人工知能(AI)技術の一つで、人間のように自然な文章を生成したり、質問に答えたりできるAIモデルです。
膨大なテキストデータとディープラーニング技術によって、前の単語の文脈に基づいて、文章内の次の単語を予測する方法を学習しています。
代表的なLLMとしては、「GPT」「BERT」「LaMDA」「PaLM」「LlaMa」などがあり、ChatGPTは、チャット向けにファインチューニングされた「GPT-3.5」を利用することで、対話型のサービスとして公開されました。
ところで、「LLM」は、何が「大規模」なのでしょうか。
「計算量」「データ量」「パラメータ数」の3つと言われています。
「計算量」が大規模
計算量とは、コンピュータが処理する仕事量のことで、LLMが学習する際には、膨大な量のデータを解析し、複雑なアルゴリズムでパターンを見つけ出します。このプロセスには、大量の計算量が必要です。

計算は、数週間から数ヶ月にわたって行われることもあり、その間に数百ペタフロップス(1ペタフロップス=1秒間に1,000兆回の計算)以上の処理が行われます。
モデルが一度構築された後でも、ユーザーからの入力に応答する際には、数百万~数十億のパラメータを参照して応答を生成するため、計算量は多くなります。
「データ量」が大規模
データ量とは、コンピュータに入力した文章データの情報量です。

LLMは、数百ギガバイトから数テラバイトにおよぶテキストデータを学習します。具体例として、書籍、ニュース記事、ウェブページ、SNSの投稿など、あらゆる形態の文章が含まれます。また、一つのトピックや言語に偏らない、多言語かつ多ジャンルのデータを取り込むことで、幅広い知識と表現力を獲得します。
ただし、取り込むデータには、適切にクリーニングされた偏りのないデータを用いることが必要になります。
「パラメータ数」が大規模
パラメータ数とは、モデルが学習によって調整する「重み」や「バイアス」の総数を指します。

重み(Weights): 入力信号の重要性を調整する値。
バイアス(Bias): モデルに基準点を加え、柔軟性を持たせる値。
パラメータが多いほど、より微細な文脈や意味の違いを理解できるようになりますが、パラメータ数が増えると、学習時や推論時に必要な計算量は大きくなります。
◆Transformerとは
多くのLLM(大規模言語モデル)で使用されているニューラルネットワークは、主に Transformer と呼ばれるアーキテクチャに基づいています。
ChatGPTのようなLLMを使用する際、プロンプトに文章を入力します。この文章は トークン と呼ばれる小さな単位に分割されます。各トークンは数値ベクトルに変換され、自己注意機構を通じて他のトークンとの関連性(重み付け)が計算されます。
この情報を元に、次に続くトークン(単語や記号)がどのようなものになるかを確率的に予測するのが、Transformerの仕組みです。
Transformerは、2017年に発表された「Attention Is All You Need」という論文で提案され、その中核にあるのが 自己注意機構(Self-Attention Mechanism) です。この機構の特徴は、入力データ内のすべての要素、例えばプロンプトに入力した文章の単語が、他の単語とどの程度関連しているかを計算し、それを基に文脈を理解する点です。
◆Transformerの構造
Transformerアーキテクチャは、エンコーダとデコーダという2つの主要な部分から成り立っています。
「エンコーダ」は、プロンプトなどから入力された文章をトークンに分割し、そのトークン間の関係性を捉える処理を行います。自然言語の理解を担当すると言えます。
「デコーダ」は、エンコーダから得た情報を基に、翻訳結果や文章の出力といった新たなトークンを生成します。自然言語の生成を担当すると言えます。
エンコーダとデコーダを組み合わせて次のトークンの予測を行う、というのがTransformerの基本構造です。
◆「Transformer」とChatGP「T」の相違点
ChatGPTの「T」はTransformerの「T」ですが、Transformerの基本的な構造とは異なった構成になっています。どのような構成になっているのでしょうか。
GPTとは

ChatGPTは、「GPT」を使ったチャットボット技術のウェブサービスです。
「GPT」は、OpenAI社が開発した自然言語処理モデルです。大量のテキストデータを学習しており、翻訳や文書生成等のタスクに利用されます。
GPT-3は1770億のパラメータを持ち、学習データセットは5000億トークン近くになると公表されています。
この結果、GPT-3は次のトークンを予測する目的で訓練(「Pre-trained」)されたLLMですが、質問への応答や翻訳など、さまざまな自然言語処理タスクが実行できるようになりました。
その後もバージョンが上がるごとにパラメータも増えているようで、GPT-3.5では3500億パラメータ以上といわれており、GPT-4ではパラメータやデータセットはより多くなっていると思われます。
GPTの処理の流れ
GPTは、Transformerのデコーダ部分のみを活用したモデルです。
GPTの基本的な動作の流れは、以下のような処理フローで行われています。
1.トークン化(Tokenization)
エンコーダの代わりに、プロンプトの文章をtokenizerでトークンに分割します。
tokenizerは事前に定義された語彙(ボキャブラリ)を基に、文章をトークンに分割します。このステップはエンコーダではなく、モデルの外部プロセスとして行われます。各トークンは語彙(ボキャブラリ)の中で一意なIDにマッピングされ、数値列に変換されます。
2.エンベディング(Embedding)
トークンIDはエンベディング層でベクトルに変換されます。これにより、トークンが数値表現として後続処理に渡されます。
───ここからがdecoderの機能になります───

3.位置エンコーディング
各トークンに「何番目の単語か」という情報である位置情報を埋め込みます。
4.Masked Self-Attention(マスク付き自己注意機能)
入力されたトークン列を基に、トークン間の関連性を計算します。アテンションスコアを通じて各トークンの文脈情報を取得し、適切な重み(どのトークンに注目するか)を割り当てます。
この機能の特徴が「Masked」という部分です。通常のSelf-Attentionでは系列全体を参照できますが、デコーダーでは未来の単語を見えないようにするため、マスクを適用します。これにより、単語を1つずつ順番に生成する形になります。
5.残差接続 & 正規化
各レイヤーの出力に元の入力を加算し、LayerNormでスケール調整を行うことで情報を保持しやすくして、学習を安定化させます。
6.フィードフォワードネットワーク(FFN)
次元圧縮や非線形変換によって各トークンの特徴を変換します。
1層目: 線形変換 → ReLU活性化、2層目:線形変換という2層を適用して、トークンごとに変換を行います。これにより各トークンごとの情報(特徴量)が強調・変換され、明確化されます。
7.残差接続 & 正規化
FFN後の情報の安定化を行います。

8.N回の繰り返し
上記4から7までを複数の層(GPT-4では48層)で繰り返すことで、より深い表現を学習します。
9.Softmax層で次の単語を予測
最後のFFNの出力スコアをSoftmaxで確率分布に変換し、最も確率が高いトークンを次のトークンとして選択します。
───ここまでがdecoderの機能になります───
10.生成の反復
予測されたトークンを入力トークン列の一番後ろに追加し、再度、1.トークン化からスタートして、次のトークンを予測します。つまり、今予測されたトークンを追加した「今までのトークン列全体」を、またデコーダに渡すということです。
GPTがエンコーダを使用しない理由
ChatGPT はユーザーからの入力(プロンプト)を受け取り、それに続く自然なテキストを生成することが主な目的です。このようなタスクでは、入力文全体を処理しつつ、それに基づいて次のトークンを逐次予測するデコーダが中心的な役割を果たします。
エンコーダは、文章分類や感情分析、翻訳モデルのソース文処理など、入力データの全体的な特徴を深く理解して出力するタスクに適しています。一方で、ChatGPTのような「次に続く文章生成」においては、デコーダのみでも十分な性能が発揮できます。

ChatGPT がエンコーダを使わない理由は、生成タスクに最適化された効率的なデザインを追求した結果です。デコーダのみでプロンプトを直接処理し、次のトークンを予測するアプローチは、応答の生成に適しています。
◆LLMの課題とは
LLMは、いくつかの課題も抱えています。

・大規模になるほど計算量は増えるため、コストも時間もかかり、電力消費や環境負荷も大きくなります。
・LLMは、ベクトル間の距離を元にした推論でテキストを生成しているので、生成されたテキストは必ずしも正確であるとは限りません。
・専門知識を学習していない場合、結果に信頼性が欠けるケースがあります。
・使い方によっては、企業の秘密情報や個人情報が漏洩し、学習されてしまうことも考えられます。
・全世界で使われているものの、LLMの使用に関しての国ごとの法規制はバラバラなのが現状です。
◆課題解決の方法
これらの課題に対して一般的には、次のような方法が知られています。
・計算量を減らすには、最適なプロンプト入力をする、
・専門知識については、必要な情報をRAG(Retrieval Augmented Generation:検索拡張生成)に格納する、
・生成AIに情報を学習させない機能を活用する。ChatGPTにはオプトアウト機能がある。
などです。
◆当社の課題解決の方法
当社では、LLMはAzure OpenAIや、Azure AI Foundry上でのDeepSeek-R1をAPIで利用する等の学習されないLLMをお勧めし、かつネットワークは閉域網で構築することをご提案しています。
生成AIソリューションとしては、確実に貴社業務でご活用いただくために、
「LLM+構造化されたRAG+AIエージェント」
をご提供しています。
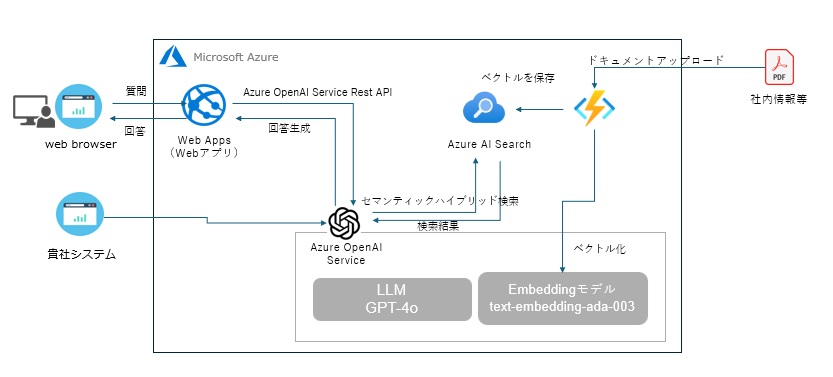
構造化されたRAGによって、貴社の情報を正しく検索することができます。文章をRAGに格納する際、構造化をしないままベクトル化すると、文章中にある表形式などを正しく読み取ることができない場合があります。その結果、得たい回答が生成されず、RAGの価値が激減してしまいます。
AIエージェントの導入で、プロンプト入力に不慣れな方でも想定通りの回答が得やすくなります。
さらに、貴社の基幹システムやDWHのデータベースとの接続も可能です。
◆LLMの今後は
LLMにはまだまだ課題はありますが、より賢くかつより効率的に、今後もLLMは進化し続けていくことでしょう。具体的には、MoEモデルの進化や、量子化・蒸留技術の進歩、DeepSeekが実装した「1.58ビット量子化」等によって、計算量や環境負荷を軽減しつつ、回答の迅速化、正解率の向上が見込めるでしょう。

インターフェイス面では、マルチモーダル化も進むと思われます。現状でもGPT-4Vは画像解析機能や音声認識が実装されています。何年後かにはプロンプト入力する必要はなく、ハンズフリーで話しかければ、音声や動画で応えてくれる・・・
セキュリティ保護や個別業務への最適化のため、追加の学習が可能なローカルLLMを選択することも広がるかもしれません。自社で軽量かつファインチューニング可能なLLMを選択し、秘密情報を学習させることで、安全で正確な回答を得ることができます。
このようにLLMは、環境への影響を抑えながらも多様な分野、あらゆる領域で活用できるような進化へと進むものと思われます。
ご相談はこちらまで
ChatGPTなどのLLMの導入にご興味がありましたら、営業統括部までご相談ください。
当社では、上記の「生成AIインテグレーションサービス」にて、貴社のLLM導入のご支援を行っております。
無料相談だけでも結構ですので、お気軽にお声がけください。

最後までお読みいただき、ありがとうございました。